Career
I've been working for a small startup high-tech company in Reno, NV, called LoadIQ. Although their domain in working with energy and electrical power consumption analysis is not a field I can say I had any experience with, my expertise with software engineering and abilities to spearhead projects were desired and a perfect fit.LoadIQ works towards building a product which can be sold to clients who are interested in potential cost-savings of energy utility bills. Although there are many sub-metering technologies out there provided by dozens of businesses, LoadIQ aims to be unique by offering "more". While the standard is to provide a description of total energy usage in either household or business/industrial settings, the "more" is to decompose (disaggregate) that total energy usage into individual component "loads", where each load represents a single electrical appliance. This means that it is possible to describe to clients exactly which appliances they are spending towards their utility bill.
My work with LoadIQ has strictly been with developing the technology that provides this level of "more" to the business. Although my responsibilities and duties have carried across many other tasks as well, this primary focus has received most of my attention. Much of this work has involved pedantic implementation tasks. Of recent, there has been more and more research involved to come up with ideas for the improvement of the disaggregation system. The potential for papers to write, either journal or technical white papers, is exciting.
From October to April I had been a "Postdoctoral Fellow" under a grant from the NSF. After that position had ended, LoadIQ kept me on the team as a "Chief Data Scientist". This position is a prestigious one, even if the company is a small one at the present.
Publications
On the front of papers and journals however, my list of publications have increased in the past several months. From my work with NASA, which had already produced one paper in the AAAI conference in March 2014, our journal version of the paper had also been accepted to IEEE Transactions of Human Machine Systems [1]. Beyond that, one of the papers I had been working on that was to be the base paper which introduced the core topic of my entire Ph.D, had also been accepted to IEEE Transactions of Software Engineering [2]. This paper was also announced as a "journal-first" paper for the ESEC/FSE 2015 conference in Bergamo, Italy. The concept of "journal-first" implies an honor that the paper was one of their best and had received the nod to also appear within a related conference.[1] J. Krall, T. Menzies, M. Davies, “Better Model-Based Analysis of Human Factors for Safe Aircraft Approach”, conditionally accepted (Nov. 2014), IEEE Transactions on Human Machine Systems
[2] J. Krall, T. Menzies, M. Davies, “Geometric Active Learning for Software Engineering”, Software Engineering, IEEE Transactions on (May 2015), doi: 10.1109/TSE.2015.2432024
The Race Condition
An interesting problem that came up recently is the race condition. This concerns the topic of mutual exclusion and producer/consumer topic, where there are N producers and M consumers which know only how to produce or consume a shared resource. While a producer may generate units for any consumer to use, it is possible, that two different consumers both grab the last remaining unit and consume it simultaneously. To solve the problem, in which two consumers are "racing" for available units, one must implement a mutual exclusion feature to make sure that resource units are excluded from those in the race that do not "come in first place".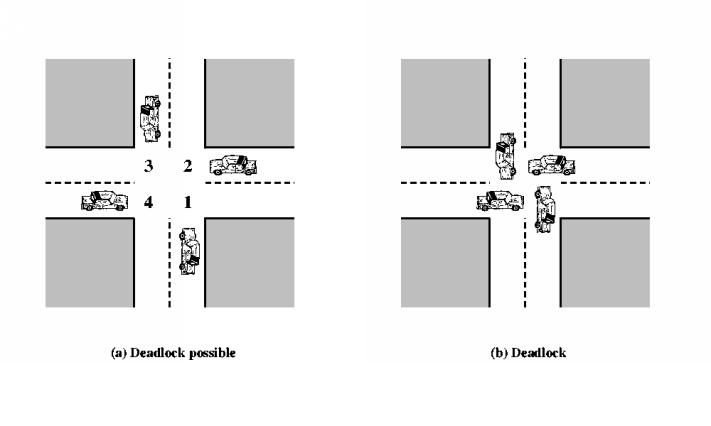
My specific problem is slightly different, but related. We have data wherein each data point is a period of energy usage of variable time length. This data is clustered into groups of similar energy usage (kilowatts of power). Reclustering the data can affect other processes, such as the process which groups the data into periods of fixed time lengths (such as five minute groupings).
The process that performs these groupings is incremental, because new data is constantly arriving, and it is more efficient to group the new data as they come, instead of grouping the entire dataset each time. This means for example, that on run #1, the first 500 periods of data are grouped. A day later when there are 100 new periods of data, run #2 will group only those periods from 500 to 600.
Meanwhile, if the data is reclustered, this affects the groupings, and they must be wiped and then started from scratch. So that after a recluster, run #3 of the grouping process will group the entire dataset from period 0 to 600.
However, there is a race condition that can occur. Suppose for example, that the grouping process begins, and it sees that it has to now group only from period 600 to 700. While that grouping process is working on that, a recluster occurs, and wipes out periods 0-600. The grouping process will finish, and we will have periods 600-700, but periods 0-600 will be wiped and gone. The next time the grouping process begins, it will see that the most recent period is 700, and it will continue to increment from 700. Meanwhile, periods 0-600 are permanently gone until the inconsistency is reset and fixed.
The solution here is to provide a mutual exclusion implementation of sorts. Whenever the recluster occurs, it must write a "wipe" flag somewhere for the grouping process to read before it ever writes any new grouping data. If the grouping process sees this "wipe" flag, it must make sure that it is processing from scratch, from period 0 and onward. However, whenever it obtains the wipe flag, it must lock other processes from affecting the flag or the period data, lest another reclustering occur before the grouping process finishes its job and groups all period data.
This 'two stage' lock is the typical solution for mutual exclusion, often known instead as a "mutex". In real life, we can think of this as physically participating in a race. Even if two people tie, they must break the tie to decide a true winner. When breaking the tie, the two people are in a state of deadlock until it is resolved, and a winner is declared who obtains the resource/prize. When waiting at a four-way stop intersection, it may be difficult to obtain the 'mutex', when everyone is waiting on everyone else to make the first move and cross the intersection.