After I finished my Ph.D, I had the opportunity to work for a startup company located in Reno, NV, called LoadIQ. The domain subject of which I would be completing my initial postdoctoral work with them was in energy and non-intrusive load monitoring (NILM). Of course this field to me at the time was a blind one -- I was a software engineer with very little to no exposure to anything electrical. Luckily, I was able to successfully dive into that field and found out that I was absorbing the material very rapidly. I thought then what I had always thought -- I was first and foremost an engineer, talented at finding out how things work. Writing code for the energy domain was no different: I had to discover that necessary understanding and then I was able to interface with the domain through my code.
Granted, there are still many things about energy that I do not know. My experience with the field is very hands-on, and I often find myself stumbling over new and old buzzwords. I have an understanding, but it is my own, with my own terminology and syntax that relates to my own coding style and the systems I engineered during my time at LoadIQ. One way to overcome this is to study as much as I can by reading research papers and looking at other companies in the energy software domain - by seeing how others talk about energy and then consolidate their words with my own.
I then later wrote a paper for the NILM Workshop back in March of 2016. My initial drafts here were certainly void of what the proper phrasings for many of my concepts were, but together with my supervisor, I was able to polish out a good submission that then later became accepted by the peer-review board for their workshop. I had written papers for publications in journals and conferences before -- this one was quite a bit less hassle as it was accepted on its first review and this I know to be a proud accomplishment.
One other way to become more engrossed with the energy domain is to work with other companies. Indeed just this week, I have the opportunity to interview with another company. From researching their company, I see right away a dozen new buzzwords making up their phraseology that were strange and new to me -- DERs, DROMS, VPP, and more. And I realized then that working with other companies was the absolute perfect way to expand my knowledge and experience with the energy domain. I am always and ever will be first a software engineer, prominent at writing code, especially Python. But new things do excite me, and I take pleasure in being able to work with new things and apply my engineering expertise to them.
One thing had always worried me: I was given the title of Chief Data Scientist -- I was the only data scientist at LoadIQ at the time, but if we were to hire and expand, I would certainly be in leadership and management roles over others. I viewed my title as one in where I was given control and leadership of how we pursued our everlasting quest for further algorithmic improvements and quality assurance. I'm proud of that, but the thing that worries me is what others think when they see the phrase "data scientist", because as I hear it, there seems to be many different styles of data science. Was I actually a data scientist or was I just a software-systems engineer?
However, the more I think of it, the less I feel confused. I believe I really am a data scientist, just not the kind most people might think of when they hear that job role. To be specific: I believe there are really only two kinds of data science. There's the more common "supervised" data science as it is related to studying training data and building models that can successfully predict missing class labels (of data in the future or past). A clear example of that is to estimate the amount of energy a building might use for a particular hour of a day in a year. By studying past data from the energy usage of that building, we can build a very solid model that can take advantage of features such as temperature, day of week, hour of the day, etc, and predict to less than 5% error margin, what the energy usage might be.
Back to LoadIQ: as a data scientist there, my primary task was a little different. Due to the nature of the product we were serving, there was no prior training data to learn from. Any model built to deliver our predictions were entirely devoid of knowing the "truth" of the class labels, and we were forced to fall back on internal consistency metrics to make sure our results were tangible enough to provide quality assurance. Moreover, our models being built were not typical of data science -- we didn't use Random Forests or Neural Networks or any other mathematical model such as Linear Regression. Instead, we had to be much more clever and devise very innovative algorithms which may in time, come to gain names of fame in our field of NILM.
As I explore my career, I remain primarily interested in "data science", whether it be unsupervised or supervised. This I realize explores a greatly nuanced field that crosses over into Machine Learning. One very interesting and simple method is called Decision Trees, which can be used in the typical model building nature of supervised data science and training data. If there's one thing you should know when you study decision trees, its to understand what is meant by "entropy and information gain". I end this blog post by leaving you a superb answer for this, written in response to a StackOverflow question by username 'Amro', located at http://stackoverflow.com/questions/1859554/what-is-entropy-and-information-gain.
Monday, December 5, 2016
Sunday, September 18, 2016
Deduplication and Connected Components
Consider a web application where users sign up with their email. Some users may sign up with multiple emails and some emails may be affiliated with multiple emails.
Code Snippit:
Users has a one-to-many relationship with duplications in this initial input, but our goal is to "deduplicate" this data so that we have many-to-many relationships without any loss of data.
Expected Output:
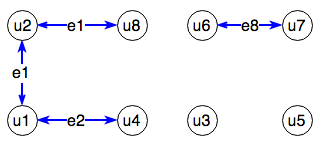
Since u1 and u2 shared e1 in common, we combined u1+u2 = e1+e2+e3. This combined user also shared in common an e2 with u4 and an e1 with u8, so ultimately, these were deduplicated into u1+u2+u4+8 = e1+e2+e3+e5+e9.
A brute force approach to solving this problem is as follows. We can iteratively make changes to the list of users, compressing it by iterating over every pair of users. In the first pass of our example, we would check u1 vs u2 for common emails. A simple set intersection will reveal any common elements shared between the two users, so if this operator shows any comparisons, we can perform a set union of both the users and emails to get the combined u1+u2 = e1+e2+e3 as desired. If there is no set intersection, we can be sure that the intersected users have no emails in common, and are distinct from each other -- for now.
At every intersection test, if we discover an intersection, we can append the combined user to a dedup_users data structure, which contains processed elements of our list of users. As expected, if we combine ui+uj, we would want to delete ui and uj from the dedup_users data structure, if they exist. In case the set union and set intersection are identical, we make sure this operation happens before we insert the combined user element into our data structure (i.e. line 10 below).
After examining every pair in our iteration, we can reprocess the list of deduplicated users again if there were any changes made. The running time complexity of such an algorithm is at best, O(N^2), because each pass requires examining every pair of users. Repeated iterations would examine smaller and smaller subsets until the subset becomes the desired deduplicated results. Another runtime analysis is to consider the use of set union and set intersection, which are both O(|u_i|+|u_j|) if i and j as the ith and jth user being compared. This means we can say that the algorithm is generally O(N^3) if the number of emails in a user is relatively small (as it probably is).
O(N^3) is not a polynomial runtime, and increasing the size of N by a factor of 10 would increase the runtime by a factor of 10*10*10 = 1000. For small user sets, we can show fair runtimes (0-10 seconds). But this quickly scales out of control for say, user sets of size 100 or more. A better algorithm is necessary if we are to expect more than 100 users.
Upon thinking about the problem a little closer, we can see that there are relationships between emails and users, and anytime you have relationships, you could utilize graph theory. In our case, we would want a graph where edges between two users represent that the two users share that edge (and edges would have the attribute to indicate its email).
In its unchanged state, our list of users would need to be inverted in a sense, so that we can see all users associated with a single email. We can do this in linear O(N) time by examining each user once, using hash tables and set theory.
With a list of 1-email to many-users, we can build our graph by iterating over pairs of users within each email. The user pairs are the nodes, and the email is an edge. If the user has only a single email, we can represent a trivial edge as an edge that goes out from the node and back into the node. This would also work in O(N) time, since every user is only visited once. To facilitate our code, we use the Network X library from Python (and have imported networkx as nx).

In the graph above, we omit trivial edges. In fact the edges don't matter all that much in terms of emails, as we can always grab the emails from the list of initial users.
Lastly, we employ our coup-de-grace to wrap this problem up. We can observe that unique user sets are disconnected from the rest of the graph. Each of these 'groupings' are called Connected Components. The Network X library employs an algorithm for connected components which is O(|V|+|E|) or O(|users| + |emails|), but we can call this O(N).
The output through Network X gives us a list of lists, where each list is a connected component containing a list of users in that group. For instance, the result on our graph here would be [[u1,u2,u4,u8], [u3], [u5], [u6,u7]]. This also gives us lists of deduplicated users, but we just have to get the emails to go with them! This leads us to our final step -- again, using set theory to union together groups of emails associated with each user in our connected components.
Finally, we can simply return the list of deduplicated users for evaluation and assurance of correctness. Overall, this graph theory approach can be described generally as O(N) * O(|connected components|). Since the number of connected components can equal as high as N in the case where every single user is perfectly distinct, this algorithm has a worst case of being O(N^2). When you think about it, it's more likely that a majority of the users are "normal" in the sense of registering only a single email each, so the average case is probably closer to O(N^2).
Secondly, we built an evaluator that would assert the correctness of the finalized results. This check involved three things: 1) did we lose any emails? 2) did we lose any users? and 3) are the users and emails listed exactly once each?
Thirdly, we wanted to test our algorithm on a variety of unbiased inputs, so we build a random generator that would construct random user and email sets. This generator takes a few inputs, namely the number of users to generate and a probability function that describes the odds of having 1 - E emails in each user. Additionally, a variety parameter was used to control the rate of collision of users having duplicated emails.
Our Brute Force algorithm is O(N^3) and the Graph Theory approach is O(N^2). Our Graph Theory approach should be much faster, right? Indeed. When run on the same set of users, we can see dramatic speeds. For larger N, these speedups would be even faster.
For one random case of 10 users, our Brute Force approach took 2.149 seconds, while our Graph Theory approach took 0.001 seconds, indicating a speedup of over 2000x. This greatly varies, since our two algorithms have different strong and weak points.
For 50 users, it is generally very difficult for the Brute Force approach to work in any bearable amount of time, while the Graph Theory approach can run in mere fractions of a second. I was able to see bearable runtimes up to N=50000 in about 9 seconds, but when we tweak the random generator so that most emails are never duplicated, the runtime for Graph Theory approach increases, and N=2000 would run in about 4 seconds (yet still, at large N, Graph Theory approach would win over Brute Force in any situation).
For details on connected components, refer to https://en.wikipedia.org/wiki/Connected_component_(graph_theory) for an overview. The general essence of any algorithm for obtaining connected components is to perform a Depth-First-Search on the graph, traversing and visiting nodes, making notes of when you need to "lift your pen" to hop to another connected component of the graph.
A similar application, Strongly Connected Components, occurs only in directed graphs. In our application, we utilized general undirected graphs, so any node within a connected component could be reached from any other node in the same connected component. With directed graphs, we encounter situations where we may not be able to return to a node once we left it. One algorithm for solving the problem of strongly connected components is Tarjan's Algorithm. The general idea here, is that any cycle or a single vertex is a strongly connected component.
This code was implemented using Python 2.7.6 and Network X 1.9.1.
Source code available here: http://pastebin.com/gKxYuEHC
Code Snippit:
1 2 3 4 5 6 7 8 9 10 | users = { tuple(['u1',]): ['e1', 'e2'], tuple(['u2',]): ['e1', 'e3'], tuple(['u3',]): ['e4'], tuple(['u4',]): ['e2', 'e5'], tuple(['u5',]): ['e6'], tuple(['u6',]): ['e7', 'e8'], tuple(['u7',]): ['e8'], tuple(['u8',]): ['e1', 'e9'] } |
Users has a one-to-many relationship with duplications in this initial input, but our goal is to "deduplicate" this data so that we have many-to-many relationships without any loss of data.
Expected Output:
1 2 3 4 5 6 7 8 9 | --((List of Deduplicated Users))-- -- Num Users: 8 -- Num Emails: 9 { ('u2', 'u8', 'u4', 'u1'): ['e9','e5','e1','e3','e2'], ('u5',): ['e6'], ('u7', 'u6'): ['e7','e8'], ('u3',): ['e4'] } |
Since u1 and u2 shared e1 in common, we combined u1+u2 = e1+e2+e3. This combined user also shared in common an e2 with u4 and an e1 with u8, so ultimately, these were deduplicated into u1+u2+u4+8 = e1+e2+e3+e5+e9.
Brute Force Approach
A brute force approach to solving this problem is as follows. We can iteratively make changes to the list of users, compressing it by iterating over every pair of users. In the first pass of our example, we would check u1 vs u2 for common emails. A simple set intersection will reveal any common elements shared between the two users, so if this operator shows any comparisons, we can perform a set union of both the users and emails to get the combined u1+u2 = e1+e2+e3 as desired. If there is no set intersection, we can be sure that the intersected users have no emails in common, and are distinct from each other -- for now.
At every intersection test, if we discover an intersection, we can append the combined user to a dedup_users data structure, which contains processed elements of our list of users. As expected, if we combine ui+uj, we would want to delete ui and uj from the dedup_users data structure, if they exist. In case the set union and set intersection are identical, we make sure this operation happens before we insert the combined user element into our data structure (i.e. line 10 below).
1 2 3 4 5 6 7 8 9 10 11 | if len(set(users[u]).intersection(set(users[v]))) > 0: try: del dedup_users[u] except: pass try: del dedup_users[v] except: pass dedup_users[tuple(list(set(u).union(set(v))))] = list(set(users[u]).union(set(users[v]))) changes_made = True |
After examining every pair in our iteration, we can reprocess the list of deduplicated users again if there were any changes made. The running time complexity of such an algorithm is at best, O(N^2), because each pass requires examining every pair of users. Repeated iterations would examine smaller and smaller subsets until the subset becomes the desired deduplicated results. Another runtime analysis is to consider the use of set union and set intersection, which are both O(|u_i|+|u_j|) if i and j as the ith and jth user being compared. This means we can say that the algorithm is generally O(N^3) if the number of emails in a user is relatively small (as it probably is).
O(N^3) is not a polynomial runtime, and increasing the size of N by a factor of 10 would increase the runtime by a factor of 10*10*10 = 1000. For small user sets, we can show fair runtimes (0-10 seconds). But this quickly scales out of control for say, user sets of size 100 or more. A better algorithm is necessary if we are to expect more than 100 users.
Graph Theory Approach
In its unchanged state, our list of users would need to be inverted in a sense, so that we can see all users associated with a single email. We can do this in linear O(N) time by examining each user once, using hash tables and set theory.
1 2 3 4 5 6 7 8 9 | #invert the users dictionary - O(|emails|) -> O(N) emails = {} for user in users: for email in users[user]: try: emails[email].add(user) except: emails[email] = set([user]) emails = {key: list(emails[key]) for key in emails} |
With a list of 1-email to many-users, we can build our graph by iterating over pairs of users within each email. The user pairs are the nodes, and the email is an edge. If the user has only a single email, we can represent a trivial edge as an edge that goes out from the node and back into the node. This would also work in O(N) time, since every user is only visited once. To facilitate our code, we use the Network X library from Python (and have imported networkx as nx).
1 2 3 4 5 6 7 8 | #build graph -- network x library - O(|emails|) -> O(N) G = nx.Graph() for email in emails: if len(emails[email]) > 1: for u1,u2 in zip(emails[email][:-1], emails[email][1:]): G.add_edge(u1, u2, email=email) else: G.add_edge(emails[email][0], emails[email][0], email=email) |
In the graph above, we omit trivial edges. In fact the edges don't matter all that much in terms of emails, as we can always grab the emails from the list of initial users.
Lastly, we employ our coup-de-grace to wrap this problem up. We can observe that unique user sets are disconnected from the rest of the graph. Each of these 'groupings' are called Connected Components. The Network X library employs an algorithm for connected components which is O(|V|+|E|) or O(|users| + |emails|), but we can call this O(N).
The output through Network X gives us a list of lists, where each list is a connected component containing a list of users in that group. For instance, the result on our graph here would be [[u1,u2,u4,u8], [u3], [u5], [u6,u7]]. This also gives us lists of deduplicated users, but we just have to get the emails to go with them! This leads us to our final step -- again, using set theory to union together groups of emails associated with each user in our connected components.
1 2 3 4 5 6 7 8 9 10 | dedup_users = {} ccs = nx.connected_components(G) #O(V+E) -> O(N) #O(N) -- every user is hit only once. Add complexity of set unions for cc in ccs: user_list = tuple([c[0] for c in cc]) email_list = set() for user in user_list: email_list = email_list.union(set(list(users[tuple([user])]))) # -> O(|users[user]|) dedup_users[user_list] = tuple(list(email_list)) |
Finally, we can simply return the list of deduplicated users for evaluation and assurance of correctness. Overall, this graph theory approach can be described generally as O(N) * O(|connected components|). Since the number of connected components can equal as high as N in the case where every single user is perfectly distinct, this algorithm has a worst case of being O(N^2). When you think about it, it's more likely that a majority of the users are "normal" in the sense of registering only a single email each, so the average case is probably closer to O(N^2).
Utility Functions
To test and assert the correctness of our two algorithms -- Brute Force and Graph Theory, we built some utility functions. First, we built a pretty printer so that we can visually output our user dictionaries and appropriately eye the correctness as the code was being implemented. This helped visually identify bugs and get to a working solution.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | def pretty_print_dict(users): """Pretty prints a dictionary of users :param: users is a dictionary to pretty print returns None """ max_n = 10 cur_n = 0 len_n = len(users) max_e = 5 max_u = 5 s = "" s += " {\n" for user in users: if (cur_n < max_n and cur_n < len_n): cur_n += 1 if len(user) < max_u: s += " " + str(user) + ": " else: s += " (" + ','.join(["'" + str(u) + "'" for u in list(user)][:max_u]) + " + " + str(len(user)-max_u) + " more...)" + ": " s += "[" cur_e = 0 len_e = len(users[user]) for e in users[user]: if (cur_e < max_e and cur_e < len_e): cur_e += 1 s += "'" + str(e) + "'" + "," else: break if cur_e < len_e: s += " + " + str(len_e - cur_e) + " more," s = s[:-1] s += "],\n" else: break if cur_n < len_n: s += " < ... " + str(len_n - cur_n) + " more keys>,\n" s = s[:-2] + "\n" s += " }" print s |
Secondly, we built an evaluator that would assert the correctness of the finalized results. This check involved three things: 1) did we lose any emails? 2) did we lose any users? and 3) are the users and emails listed exactly once each?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | def assert_correctness(users, correct_num_users, correct_num_emails): """Assert the correctness of the deduplication process :param: users is the deduplicated dictionary of users to assert correctness :param: correct_num_users is the expected number of unique users :param: correct_num_emails is the expected number of unique emails returns None -- output result is printed here instead Explanation: A dictionary of users is deduplicated if the set of unique users and emails found throughout the dictionary amount to the same amount of users we started with. This ensures we did not lose any information. Second, we require that no email found in any user is found in any other user. This ensures that the dupication clause is correct. """ #Test of the Loss of Data Clause set_users = set([]) set_emails = set([]) for key in users: for item in key: set_users.add(item) for val in users[key]: set_emails.add(val) #Test the duplication clause violations_found = 0 already_probed = {} for user in users: for other_user in users: if not user == other_user and not already_probed.get((user, other_user), False): already_probed[(user,other_user)] = True if len(set(list(users[user])).intersection(set(list(users[other_user])))) > 0: violations_found += 1 #Pretty print deduplicated users print "\n--((List of Deduplicated Users))--" print " -- Num Users: " + str(len(set_users)) print " -- Num Emails: " + str(len(set_emails)) pretty_print_dict(users) #Print out report print "\n--((Assertion Evaluation))--" print " -- Users look unique and correct!" if len(set_users) == correct_num_users else " -- These users don't look right." print " -- Emails look unique and correct!" if len(set_emails) == correct_num_emails else " -- These emails don't look right." print " -- Duplication Violations found: " + str(violations_found) |
Thirdly, we wanted to test our algorithm on a variety of unbiased inputs, so we build a random generator that would construct random user and email sets. This generator takes a few inputs, namely the number of users to generate and a probability function that describes the odds of having 1 - E emails in each user. Additionally, a variety parameter was used to control the rate of collision of users having duplicated emails.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | def gen_random_users(N = 10, tiers = [0.70, 0.80, 0.90, 0.95, 0.98, 0.99, 0.999], V = 1): """generates a random dictionary of users and emails :param: N controls the number of users to be generated :param: tiers controls the probabilities of increasing numbers of emails per user :param: V controls the variety of the emails generated. Higher V = less chance of duplicate returns users - a list of random users with random emails """ users = {} set_emails = set([]) variety = V*N/10 for i in range(1,N+1): #gen random list of emails f = random.random() for t,tier in enumerate(tiers): if f < tier: n = t+1 break emails = [] for j in range(n): emails.append(random.randint(1,10+variety)) emails = list(set(emails)) emails = ['e'+str(e) for e in emails] for email in emails: set_emails.add(email) users[tuple(['u'+str(i),])] = emails return users, N, len(set_emails) |
Comparing Brute Force to Graph Theory
Our Brute Force algorithm is O(N^3) and the Graph Theory approach is O(N^2). Our Graph Theory approach should be much faster, right? Indeed. When run on the same set of users, we can see dramatic speeds. For larger N, these speedups would be even faster.
For one random case of 10 users, our Brute Force approach took 2.149 seconds, while our Graph Theory approach took 0.001 seconds, indicating a speedup of over 2000x. This greatly varies, since our two algorithms have different strong and weak points.
For 50 users, it is generally very difficult for the Brute Force approach to work in any bearable amount of time, while the Graph Theory approach can run in mere fractions of a second. I was able to see bearable runtimes up to N=50000 in about 9 seconds, but when we tweak the random generator so that most emails are never duplicated, the runtime for Graph Theory approach increases, and N=2000 would run in about 4 seconds (yet still, at large N, Graph Theory approach would win over Brute Force in any situation).
Connected Components
A similar application, Strongly Connected Components, occurs only in directed graphs. In our application, we utilized general undirected graphs, so any node within a connected component could be reached from any other node in the same connected component. With directed graphs, we encounter situations where we may not be able to return to a node once we left it. One algorithm for solving the problem of strongly connected components is Tarjan's Algorithm. The general idea here, is that any cycle or a single vertex is a strongly connected component.
Full Source Code
Source code available here: http://pastebin.com/gKxYuEHC
Tuesday, September 13, 2016
Week of Code - Sorting Algorithms
The topic of Sorting Algorithms is a very key subject within computer science algorithms study, as it is often frequently used in much larger coding projects. There are a number of well-known algorithms, such as Merge Sort, Quick Sort, Insertion Sort and Bubble Sort, which should be well-studied by the avid computer scientist. Before one could properly analyze each, we need to assume an understanding of Big-O Notation and algorithmic complexity analysis.
In this blog post, we look at some of these popular sorting algorithms and implement them in Python. I've set up a way to benchmark the speeds of each and verify their correctness, and we will be able to see how they perform under different characteristics.
This algorithm essentially iterates over the array from left to right. At each item, it then searches for an item to the right of it that it needs to swap. After passing through each item in this manner, it follows that all of the items will be ordered properly.
The outer loop will always run n-many times. The inner loop varies from running one time during each pass (the best case), or n-i many times times in each pass (the worst case). One exercise is to consider when these cases happen. For instance, when the list is in reverse order, we can expect the worst case. The best case on the other hand, will happen when the list is already nearly sorted.
It follows that the the worst case of Bubble Sort is O(N²), but its best case can be O(N). A python implementation above shows best-of-5 runtimes for Bubble Short as follows. Every time the size of the list increased ten-fold, the runtime increased one-hundred-fold. For mostly sorted lists, the runtime was about 33% faster.
Indeed, some argue that Bubble Sort isn't even worthwhile to teach others, due to how fast it scales in runtime as the size of the sorting list grows. However, I argue that the simplicity of the sort offers an incubational problem solving environment to many who wish to begin studying algorithms.
Ultimately, the insertion sort will still iterate over each element once in the outer loop. It then makes a note of the index at that location, and then begins to iterate backwards looking for inversions that need to be corrected by inserting the out-of-order element before the indexed position.
One other way to understand this algorithm is to consider a hand of cards that you need to sort. Typically, you'd look at the first card, and then scan right of it looking for any cards smaller than it, and you'd insert those before your first card in sorted order.
At its worst case, the Insertion sort requires N passes of the outer loop and N-i passes of the inner loop, which could happen if the list was reverse-sorted. This is O(N²) at worst case, but O(N) at its best case. This sounds identical to Bubble Sort, but why is Insertion Sort faster than Bubble Sort at its best case? The code for our Insertion Sort can utilize a While loop in its inner loop, whereas the Bubble Sort used a For loop. In the best case for Bubble Sort, it still had to iterate over N-i items in every inner loop. However, the Insertion Sort code can opt out of its Inner While loop at any time, and on the very first pass of best cases.
The runtime analyses still demonstrates the scale of quadratic complexity. Every time N increases by one order of magnitude, the runtime increased by two orders of magnitude. It's worth noting that in practice, people tend to sort lists that are already sorted, meaning that the "mostly sorted" case is more frequent than a totally random list. This is a good feature of Insertion Sort, but as we will see, there are far better sorting algorithms.
To ensure the correctness of our algorithms, we ran them through a verify_correct() method which iterates over every subsequent pair of elements to ensure that they were ordered properly.
Our benchmark tool ran for N = 10, 100, 1000 and 10000 elements, and for both randomized lists and slightly-out-of-order lists. For each level of N and orderliness, we ran the sorting algorithm 5 times and chose the best runtime (best-of-five), meaning that every sorting algorithm ran 5*4*2 = 40 times.
Code available at: http://pastebin.com/YwY5K404
In this blog post, we look at some of these popular sorting algorithms and implement them in Python. I've set up a way to benchmark the speeds of each and verify their correctness, and we will be able to see how they perform under different characteristics.
Bubble Sort
We start with perhaps the most trivial sorting algorithm - the Bubble Sort.1 2 3 4 5 6 7 8 | def bubbleSort(arr): larr = len(arr) for i in np.arange(larr): for j in np.arange(larr - i - 1): if arr[j] > arr[j+1]: temp = arr[j+1] arr[j+1] = arr[j] arr[j] = temp |
This algorithm essentially iterates over the array from left to right. At each item, it then searches for an item to the right of it that it needs to swap. After passing through each item in this manner, it follows that all of the items will be ordered properly.
The outer loop will always run n-many times. The inner loop varies from running one time during each pass (the best case), or n-i many times times in each pass (the worst case). One exercise is to consider when these cases happen. For instance, when the list is in reverse order, we can expect the worst case. The best case on the other hand, will happen when the list is already nearly sorted.
It follows that the the worst case of Bubble Sort is O(N²), but its best case can be O(N). A python implementation above shows best-of-5 runtimes for Bubble Short as follows. Every time the size of the list increased ten-fold, the runtime increased one-hundred-fold. For mostly sorted lists, the runtime was about 33% faster.
Indeed, some argue that Bubble Sort isn't even worthwhile to teach others, due to how fast it scales in runtime as the size of the sorting list grows. However, I argue that the simplicity of the sort offers an incubational problem solving environment to many who wish to begin studying algorithms.
| Mostly Sorted? | N | Runtime (s) |
| No | 10 | 0.00012 |
| Yes | 10 | 0.00011 |
| No | 100 | 0.00349 |
| Yes | 100 | 0.00227 |
| No | 1000 | 0.32612 |
| Yes | 1000 | 0.20100 |
| No | 10000 | 33.4892 |
| Yes | 10000 | 20.6090 |
Insertion Sort
The Insertion Sort, like Bubble Sort, is not a very fast sort although it is still a relatively simple sorting algorithm. While it remains of the same class of algorithms as Bubble Sort, the Insertion Sort has a much faster potential if the list is already mostly sorted.1 2 3 4 5 6 7 8 | def insertionSort(arr): for i in np.arange(1, len(arr)): currentvalue = arr[i] position = i while position > 0 and arr[position-1] > currentvalue: arr[position] = arr[position-1] position = position-1 arr[position] = currentvalue |
Ultimately, the insertion sort will still iterate over each element once in the outer loop. It then makes a note of the index at that location, and then begins to iterate backwards looking for inversions that need to be corrected by inserting the out-of-order element before the indexed position.
One other way to understand this algorithm is to consider a hand of cards that you need to sort. Typically, you'd look at the first card, and then scan right of it looking for any cards smaller than it, and you'd insert those before your first card in sorted order.
At its worst case, the Insertion sort requires N passes of the outer loop and N-i passes of the inner loop, which could happen if the list was reverse-sorted. This is O(N²) at worst case, but O(N) at its best case. This sounds identical to Bubble Sort, but why is Insertion Sort faster than Bubble Sort at its best case? The code for our Insertion Sort can utilize a While loop in its inner loop, whereas the Bubble Sort used a For loop. In the best case for Bubble Sort, it still had to iterate over N-i items in every inner loop. However, the Insertion Sort code can opt out of its Inner While loop at any time, and on the very first pass of best cases.
The runtime analyses still demonstrates the scale of quadratic complexity. Every time N increases by one order of magnitude, the runtime increased by two orders of magnitude. It's worth noting that in practice, people tend to sort lists that are already sorted, meaning that the "mostly sorted" case is more frequent than a totally random list. This is a good feature of Insertion Sort, but as we will see, there are far better sorting algorithms.
| Mostly Sorted? | N | Runtime (s) |
| No | 10 | 0.00003 |
| Yes | 10 | 0.00003 |
| No | 100 | 0.00213 |
| Yes | 100 | 0.00029 |
| No | 1000 | 0.20506 |
| Yes | 1000 | 0.02768 |
| No | 10000 | 20.7122 |
| Yes | 10000 | 2.39983 |
Merge Sort
The Merge Sort is one of our more complex algorithms, and more generally, a Divide-and-Conquer algorithm. Using recursion, the problem size is divided into most basic elements (lists of size 1), and then they are "conquered" by recombining them into a sorted parts, and then finally into a sorted whole.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | def mergeSortLen(part): """takes an unsorted list and returns a sorted list """ if len(part) > 1: mid = len(part)/2 left = mergeSortLen(part[:mid]) right = mergeSortLen(part[mid:]) i = 0 j = 0 k = 0 llen = len(left) rlen = len(right) while i < llen and j < rlen: if left[i] > right[j]: part[k] = right[j] j += 1 else: part[k] = left[i] i += 1 k += 1 if i < j: remaining = left remlen = llen r = i else: remaining = right remlen = rlen r = j while r < remlen: part[k] = remaining[r] r += 1 k += 1 return part else: return part |
The source code for Merge Sort is much more complex than Insertion Sort or Bubble Sort, but the pay-off is worth it. An understanding of Merge Sort assumes an understanding of basic Recursion. That is, the code will call itself on a smaller part of the input until the input becomes so small it matches the recursive base case, at which point it no longer calls itself, but proceeds to reconstruct the pieces in a sorted fashion.
Consider an unsorted list:
374591
This would first be split (as into a leaf and leaf nodes) into:
374 and 591
Which then would further keep splitting:
3 & 74 and 5 & 91
7 & 4 9 & 1
Once the tree has been split into each of its leaf nodes, we can then begin reconstructing the list by marrying leaf nodes with its direct sibling node. Our lowest two pairs of sibling-pair leaf nodes are "7 & 4" and "9 & 1". These are both inverted, so the reconstruction would swap them into "4 & 7" and "1 & 9".
At this point, our recombination would need to marry "3 & 47" and also marry "5 & 19". The sorting technique here is to place pointers on both sides. At each step, we compare two elements, selecting the smaller of the two to be placed into the joined list. For instance, with "3 & 47", we'd compare 3 vs 4, selecting the 3 to go into the first spot of the joined list. And then we'd pick the 4, and then the 7, so we'd have a joined list of "347". For "5 & 19", we'd have to pick 1 first, and then the 5 and 9.
This gives us a tree which looks like:
347 and 159
One final recombination step initializes pointers at the 3 and 1. Since 1 is smaller, we select it first, which advances the right-side pointer to the 5, so that we are comparing 3 vs 5. Pick the 3, and then we're comparing 4 vs 5, and so on. The final combination gives us our final sorted list of 134579.
In our code, it is possible that our pointers exhaust one of the two sides before it exhausts the other. in this case, we have to handle remaining elements and sort them in a similar fashion.
The analysis of Merge Sort could be solved with Recurrence Relations. There are two recursive calls which operate on half of the input, and then there is a linear O(N) section that follows the recursive calls to recombine the pieces. Hence, T(N) = 2T(N/2) + O(N), which is of the form, aT(N/b) + f(N), and we can use the Master Theorem's case two to show that T(N) = O(N log N), and that the best case and worst case are the same.
The runtime of Merge Sort can vary greatly on its actual implementation. In our code, we utilize the len() method as little as possible to achieve a fairly minimal runtime. For a list with 10000 elements, we can see that the runtime is about 500 times faster than Bubble Sort, and even ~33 times faster than Insertion Sort in its best case. We can also see that Merge Sort has very little variance in the runtimes between mostly sorted lists and totally random lists, which follows from the fact that its best and worst cases are of the same complexity.
The analysis of Merge Sort could be solved with Recurrence Relations. There are two recursive calls which operate on half of the input, and then there is a linear O(N) section that follows the recursive calls to recombine the pieces. Hence, T(N) = 2T(N/2) + O(N), which is of the form, aT(N/b) + f(N), and we can use the Master Theorem's case two to show that T(N) = O(N log N), and that the best case and worst case are the same.
The runtime of Merge Sort can vary greatly on its actual implementation. In our code, we utilize the len() method as little as possible to achieve a fairly minimal runtime. For a list with 10000 elements, we can see that the runtime is about 500 times faster than Bubble Sort, and even ~33 times faster than Insertion Sort in its best case. We can also see that Merge Sort has very little variance in the runtimes between mostly sorted lists and totally random lists, which follows from the fact that its best and worst cases are of the same complexity.
| Mostly Sorted? | N | Runtime (s) |
| No | 10 | 0.00003 |
| Yes | 10 | 0.00003 |
| No | 100 | 0.00058 |
| Yes | 100 | 0.00055 |
| No | 1000 | 0.00643 |
| Yes | 1000 | 0.00496 |
| No | 10000 | 0.06727 |
| Yes | 10000 | 0.06211 |
Quick Sort
Like Merge Sort, the Quick Sort is a recursive Divide-and-Conquer function. Its primary difference is that it relies on the selection of a pivot to decide on how to split the parts into two. After the parts are split, the "conquering" recombination portion of the code is moot, because all that is needed is to recombine the pieces as each side will be ready to marry in perfect sort order.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | def quicksort(arr): quicksorthelper(arr, 0, len(arr)-1) def quicksorthelper(arr, first, last): if first < last: pivot = partition(arr, first, last) quicksorthelper(arr, first, pivot-1) quicksorthelper(arr, pivot+1, last) def partition(arr, first, last) : pivot = last swap(arr, pivot, last) for i in np.arange(first, last): if arr[i] <= arr[last]: swap(arr, i, first) first += 1 swap(arr, first, last) return first def swap(A, x, y): A[x],A[y]=A[y],A[x] |
The selection of a pivot for Quick Sort is a big topic. In general, three easy choices can be either the first element, the last element or the middle element. In this source code, we select the last element, because it is known that Quick Sort can be slow if it chooses the first element on an already sorted list.
Quick Sort works as follows. After selection of a pivot, the list is divided into the section to the left and right of the pivot (of its value, not index). The elements of each side are then recursively sorted in the same way. The recombination step has nothing to do, since the pivot partition was done in such a way that elements greater than the pivot were moved into the right side, and elements less than the pivot are moved into the left side.
Asymptotically, Quick Sort is in the average case, an O(N log N) algorithm, however its worst case can be O(N²). This can happen in the case of an unbalanced splitting of the list, e.g. one side has all of the elements on every split. This can make the selection of the pivot a very important factor. The reason the first element is often a poor choice is because in practice, lists are usually already sorted or mostly sorted, which can lead to poor performance behavior.
Indeed, we see that for mostly-sorted lists, Quick Sort performs much worse. However, it is still far faster than Bubble Sort and Insertion Sort. Compared to Merge Sort, there is basically no difference except for its mostly-sorted case.
| Mostly Sorted? | N | Runtime (s) |
| No | 10 | 0.00002 |
| Yes | 10 | 0.00005 |
| No | 100 | 0.00036 |
| Yes | 100 | 0.00084 |
| No | 1000 | 0.00559 |
| Yes | 1000 | 0.01608 |
| No | 10000 | 0.06909 |
| Yes | 10000 | 0.16705 |
Tim Sort
So far, we could argue that Merge Sort is a clear winner of all algorithms shown so far. How could one make Merge Sort faster? Python's native sorting algorithm is one called Tim Sort, which is a hybrid algorithm that combines features of both the Merge Sort and Insertion Sort. We have seen that Insertion Sort performs very well on mostly-already sorted sequences. In Tim Sort, the algorithm finds subsequences of mostly-sorted data and exploits those regions to more efficiently sort the remaining portions.
The source code for using Tim Sort is basically to just call the sort() method on any list data that can be sorted. We use a wrapper to bring benchmarks on the sorting algorithm for comparison with the others.
As we can see, the runtimes for Tim Sort are improved with mostly-sorted lists, and even in its slower cases, it is about 20 times faster than even Merge Sort, and up to 40 times faster for already-sorted lists. Asymptotically, Tim Sort is worst case O(N log N) and best case of O(N), making Tim Sort a linear algorithm at best.
1 2 | def timsort(arr): arr.sort() |
The source code for using Tim Sort is basically to just call the sort() method on any list data that can be sorted. We use a wrapper to bring benchmarks on the sorting algorithm for comparison with the others.
As we can see, the runtimes for Tim Sort are improved with mostly-sorted lists, and even in its slower cases, it is about 20 times faster than even Merge Sort, and up to 40 times faster for already-sorted lists. Asymptotically, Tim Sort is worst case O(N log N) and best case of O(N), making Tim Sort a linear algorithm at best.
| Mostly Sorted? | N | Runtime (s) |
| No | 10 | 0 |
| Yes | 10 | 0 |
| No | 100 | 0.00002 |
| Yes | 100 | 0.00001 |
| No | 1000 | 0.00027 |
| Yes | 1000 | 0.00015 |
| No | 10000 | 0.00369 |
| Yes | 10000 | 0.00154 |
Utility Source Code
We used a random list generator that used Numpy. To ensure sparsity of the generated random numbers, we make the range of numbers to generate much bigger than the number of elements that is needed. To generate mostly sorted lists, we took 5% of the elements and inverted them randomly.To ensure the correctness of our algorithms, we ran them through a verify_correct() method which iterates over every subsequent pair of elements to ensure that they were ordered properly.
Our benchmark tool ran for N = 10, 100, 1000 and 10000 elements, and for both randomized lists and slightly-out-of-order lists. For each level of N and orderliness, we ran the sorting algorithm 5 times and chose the best runtime (best-of-five), meaning that every sorting algorithm ran 5*4*2 = 40 times.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | def genRandomList(n = 21, neatness = 0.50, sparsity=20): return list(np.random.randint(low=-n*sparsity, high=n*sparsity, size=n)) def genMostlySortedList(n = 21, neatness = 0.50, sparsity=20): arr = list(np.random.randint(low=-n*sparsity, high=n*sparsity, size=n)) arr.sort() f = 0.05 larr = len(arr) for i in range(int(f * larr) + 1): x = random.randint(0, larr-1) y = random.randint(0, larr-1) temp = arr[x] arr[x] = arr[y] arr[y] = temp return arr def verify_correct(arr): for item,next in zip(arr[:-1], arr[1:]): if item <= next: continue else: return False return True def benchmark(method): for n in [10, 100]:#, 1000, 10000]: best_runtime = None correctness = True for repeat in range(5): x = genRandomList(n=n) time_of_start = time.time() method(x) time_of_end = time.time() if best_runtime is None: best_runtime = time_of_end - time_of_start else: best_runtime = min(best_runtime, time_of_end - time_of_start) correctness = correctness and verify_correct(x) print "{:<20s}".format(str(method.__name__)) + ", " + "mostly sorted=False" + ", " + "{:<8s}".format(str(n)) + ", " + str("%.5f" % (best_runtime)) + ", " + str("correct" if correctness else "incorrect") best_runtime = None correctness = True for repeat in range(5): x = genMostlySortedList(n=n) time_of_start = time.time() method(x) time_of_end = time.time() if best_runtime is None: best_runtime = time_of_end - time_of_start else: best_runtime = min(best_runtime, time_of_end - time_of_start) correctness = correctness and verify_correct(x) print "{:<20s}".format(str(method.__name__)) + ", " + "mostly sorted=True " + ", " + "{:<8s}".format(str(n)) + ", " + str("%.5f" % (best_runtime)) + ", " + str("correct" if correctness else "incorrect") print "-----------------------------------------------------------" |
Test Driver
Finally, to run our code, we ran the benchmark() method on each of our sorting algorithms, passing along the function call of each method to be benchmarked. The result is a print-out of the performance of each algorithm.1 2 3 4 5 | benchmark(mergeSortLen) benchmark(timsort) benchmark(quicksort) benchmark(insertionSort) benchmark(bubbleSort) |
Full Code
The full code was written with Python 2.7.8 and Numpy 1.9.0.Code available at: http://pastebin.com/YwY5K404
Friday, January 29, 2016
Distance Metrics - Part 1
In the world of data science, one important metric that comes up is the distance metric. How do you measure the difference between two data objects? What if the data objects are multi-dimensional? The choice of distance metric is an important one that can change the outcome of your data analyses. So it's a good idea to review some of the popular and often-used metrics for an understanding of which one applies to your data.
Define a "data object" as a numerically valued profile. Each value within the profile attributes itself to a real number. If a data object consists of N dimensions, then it has N real numbers that define its profile.
Manhattan Distance & Euclidean Distance
Often called city-block distance, the Manhattan distance is a very simple metric which measures the sum of the (absolute) differences in each dimension. Consider an example in measuring the distance between two data objects: [21, 15, 19] and [32, 47, 10]. The first dimension in each object is 21 and 32, respectively. The second dimension in each object is 15 and 47, respectively, and so on. The Manhattan distance measures the difference between these two objects as abs(21-32) + abs(15-47) + abs(19-10) = 11 + 32 + 9 = 52. That is, the Manhattan Distance between these two example data objects is 52. The units are unimportant in this example, but when considering your data, the units depends on what you're working with.
It's easy to see when the Manhattan distance makes sense to use and when it does not. In a two-dimensional plane, the city-block distance sums the differences in both the x-axis and y-axis directions. It may make better sense to instead use a metric which takes the birds-eye distance in a straight line, i.e. the Euclidean Distance. In the image below, two data objects, labeled A and B, are being compared. In this case, each data object is two-dimension. The Manhattan distance between A and B is taken by measuring the length of the purple lines, and the Euclidean distance is taken as the yellow line between points A and B. As you can see, the Euclidean distance in this case is smaller than the Manhattan distance, as the city-block path goes out of its way in travelling from point A to B. In a city setting, the city-block distance makes sense, because you can only go where the roads take you, and the roads are typically laid out in a fashion such that you can't drive through the blocks themselves, because you know, ... buildings and such.
 |
| Manhattan vs. Euclidean |
In analyzing the general effectiveness of Manhattan vs. Euclidean, it is a good rule of thumb to suggest that Manhattan may be best for single dimensions, and Euclidean is best for two dimensions or more. Perhaps we should leave that at two dimensions for Euclidean, however. As the dimensional space becomes more complex, we will see that due to the nature of the how the Euclidean distance behaves, some aspects of the the data may become over-accentuated when they need not be, or should not be. In addition, the Euclidean distance will give equal precedence to each dimension, when this may or may not be what your data needs.
In the area of wavelets, a single data object may consist of say, 32 dimensions. Each dimension is a real-valued number. The question of comparing two wavelets comes down to comparing two 32-dimensional data objects.
 |
| A typical wavelet |
In power & energy research, for a particular kind of data, consider wavelets which are, on most of the dimensional attributes of different data objects, about 80% similar. Only a handful of the 32 values along the wavelets are significantly different enough to care about. In this case, the Euclidean distance metric may not be the best tool at hand for measuring the difference in two wavelets, because of 1) the over-accentuation of dimensional attributes which are very different than the rest, and 2) the idea that the metric gives equal attention to all attributes, even when some of them aren't significant.
There are a handful of other distance metrics which may be better; for example: Mahalanobis, Minkowski, Canberra, and more. Stay tuned for more about these metrics in my next blog post.
Further Reading
There are several callouts to research papers in the following community posts:
http://stats.stackexchange.com/questions/99171/why-is-euclidean-distance-not-a-good-metric-in-high-dimensions
http://stats.stackexchange.com/questions/29627/euclidean-distance-is-usually-not-good-for-sparse-data
Subscribe to:
Posts (Atom)