Code Snippit:
1 2 3 4 5 6 7 8 9 10 | users = { tuple(['u1',]): ['e1', 'e2'], tuple(['u2',]): ['e1', 'e3'], tuple(['u3',]): ['e4'], tuple(['u4',]): ['e2', 'e5'], tuple(['u5',]): ['e6'], tuple(['u6',]): ['e7', 'e8'], tuple(['u7',]): ['e8'], tuple(['u8',]): ['e1', 'e9'] } |
Users has a one-to-many relationship with duplications in this initial input, but our goal is to "deduplicate" this data so that we have many-to-many relationships without any loss of data.
Expected Output:
1 2 3 4 5 6 7 8 9 | --((List of Deduplicated Users))-- -- Num Users: 8 -- Num Emails: 9 { ('u2', 'u8', 'u4', 'u1'): ['e9','e5','e1','e3','e2'], ('u5',): ['e6'], ('u7', 'u6'): ['e7','e8'], ('u3',): ['e4'] } |
Since u1 and u2 shared e1 in common, we combined u1+u2 = e1+e2+e3. This combined user also shared in common an e2 with u4 and an e1 with u8, so ultimately, these were deduplicated into u1+u2+u4+8 = e1+e2+e3+e5+e9.
Brute Force Approach
A brute force approach to solving this problem is as follows. We can iteratively make changes to the list of users, compressing it by iterating over every pair of users. In the first pass of our example, we would check u1 vs u2 for common emails. A simple set intersection will reveal any common elements shared between the two users, so if this operator shows any comparisons, we can perform a set union of both the users and emails to get the combined u1+u2 = e1+e2+e3 as desired. If there is no set intersection, we can be sure that the intersected users have no emails in common, and are distinct from each other -- for now.
At every intersection test, if we discover an intersection, we can append the combined user to a dedup_users data structure, which contains processed elements of our list of users. As expected, if we combine ui+uj, we would want to delete ui and uj from the dedup_users data structure, if they exist. In case the set union and set intersection are identical, we make sure this operation happens before we insert the combined user element into our data structure (i.e. line 10 below).
1 2 3 4 5 6 7 8 9 10 11 | if len(set(users[u]).intersection(set(users[v]))) > 0: try: del dedup_users[u] except: pass try: del dedup_users[v] except: pass dedup_users[tuple(list(set(u).union(set(v))))] = list(set(users[u]).union(set(users[v]))) changes_made = True |
After examining every pair in our iteration, we can reprocess the list of deduplicated users again if there were any changes made. The running time complexity of such an algorithm is at best, O(N^2), because each pass requires examining every pair of users. Repeated iterations would examine smaller and smaller subsets until the subset becomes the desired deduplicated results. Another runtime analysis is to consider the use of set union and set intersection, which are both O(|u_i|+|u_j|) if i and j as the ith and jth user being compared. This means we can say that the algorithm is generally O(N^3) if the number of emails in a user is relatively small (as it probably is).
O(N^3) is not a polynomial runtime, and increasing the size of N by a factor of 10 would increase the runtime by a factor of 10*10*10 = 1000. For small user sets, we can show fair runtimes (0-10 seconds). But this quickly scales out of control for say, user sets of size 100 or more. A better algorithm is necessary if we are to expect more than 100 users.
Graph Theory Approach
In its unchanged state, our list of users would need to be inverted in a sense, so that we can see all users associated with a single email. We can do this in linear O(N) time by examining each user once, using hash tables and set theory.
1 2 3 4 5 6 7 8 9 | #invert the users dictionary - O(|emails|) -> O(N) emails = {} for user in users: for email in users[user]: try: emails[email].add(user) except: emails[email] = set([user]) emails = {key: list(emails[key]) for key in emails} |
With a list of 1-email to many-users, we can build our graph by iterating over pairs of users within each email. The user pairs are the nodes, and the email is an edge. If the user has only a single email, we can represent a trivial edge as an edge that goes out from the node and back into the node. This would also work in O(N) time, since every user is only visited once. To facilitate our code, we use the Network X library from Python (and have imported networkx as nx).
1 2 3 4 5 6 7 8 | #build graph -- network x library - O(|emails|) -> O(N) G = nx.Graph() for email in emails: if len(emails[email]) > 1: for u1,u2 in zip(emails[email][:-1], emails[email][1:]): G.add_edge(u1, u2, email=email) else: G.add_edge(emails[email][0], emails[email][0], email=email) |
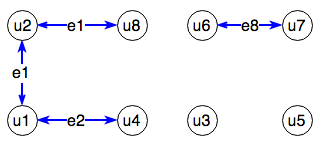
In the graph above, we omit trivial edges. In fact the edges don't matter all that much in terms of emails, as we can always grab the emails from the list of initial users.
Lastly, we employ our coup-de-grace to wrap this problem up. We can observe that unique user sets are disconnected from the rest of the graph. Each of these 'groupings' are called Connected Components. The Network X library employs an algorithm for connected components which is O(|V|+|E|) or O(|users| + |emails|), but we can call this O(N).
The output through Network X gives us a list of lists, where each list is a connected component containing a list of users in that group. For instance, the result on our graph here would be [[u1,u2,u4,u8], [u3], [u5], [u6,u7]]. This also gives us lists of deduplicated users, but we just have to get the emails to go with them! This leads us to our final step -- again, using set theory to union together groups of emails associated with each user in our connected components.
1 2 3 4 5 6 7 8 9 10 | dedup_users = {} ccs = nx.connected_components(G) #O(V+E) -> O(N) #O(N) -- every user is hit only once. Add complexity of set unions for cc in ccs: user_list = tuple([c[0] for c in cc]) email_list = set() for user in user_list: email_list = email_list.union(set(list(users[tuple([user])]))) # -> O(|users[user]|) dedup_users[user_list] = tuple(list(email_list)) |
Finally, we can simply return the list of deduplicated users for evaluation and assurance of correctness. Overall, this graph theory approach can be described generally as O(N) * O(|connected components|). Since the number of connected components can equal as high as N in the case where every single user is perfectly distinct, this algorithm has a worst case of being O(N^2). When you think about it, it's more likely that a majority of the users are "normal" in the sense of registering only a single email each, so the average case is probably closer to O(N^2).
Utility Functions
To test and assert the correctness of our two algorithms -- Brute Force and Graph Theory, we built some utility functions. First, we built a pretty printer so that we can visually output our user dictionaries and appropriately eye the correctness as the code was being implemented. This helped visually identify bugs and get to a working solution.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | def pretty_print_dict(users): """Pretty prints a dictionary of users :param: users is a dictionary to pretty print returns None """ max_n = 10 cur_n = 0 len_n = len(users) max_e = 5 max_u = 5 s = "" s += " {\n" for user in users: if (cur_n < max_n and cur_n < len_n): cur_n += 1 if len(user) < max_u: s += " " + str(user) + ": " else: s += " (" + ','.join(["'" + str(u) + "'" for u in list(user)][:max_u]) + " + " + str(len(user)-max_u) + " more...)" + ": " s += "[" cur_e = 0 len_e = len(users[user]) for e in users[user]: if (cur_e < max_e and cur_e < len_e): cur_e += 1 s += "'" + str(e) + "'" + "," else: break if cur_e < len_e: s += " + " + str(len_e - cur_e) + " more," s = s[:-1] s += "],\n" else: break if cur_n < len_n: s += " < ... " + str(len_n - cur_n) + " more keys>,\n" s = s[:-2] + "\n" s += " }" print s |
Secondly, we built an evaluator that would assert the correctness of the finalized results. This check involved three things: 1) did we lose any emails? 2) did we lose any users? and 3) are the users and emails listed exactly once each?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | def assert_correctness(users, correct_num_users, correct_num_emails): """Assert the correctness of the deduplication process :param: users is the deduplicated dictionary of users to assert correctness :param: correct_num_users is the expected number of unique users :param: correct_num_emails is the expected number of unique emails returns None -- output result is printed here instead Explanation: A dictionary of users is deduplicated if the set of unique users and emails found throughout the dictionary amount to the same amount of users we started with. This ensures we did not lose any information. Second, we require that no email found in any user is found in any other user. This ensures that the dupication clause is correct. """ #Test of the Loss of Data Clause set_users = set([]) set_emails = set([]) for key in users: for item in key: set_users.add(item) for val in users[key]: set_emails.add(val) #Test the duplication clause violations_found = 0 already_probed = {} for user in users: for other_user in users: if not user == other_user and not already_probed.get((user, other_user), False): already_probed[(user,other_user)] = True if len(set(list(users[user])).intersection(set(list(users[other_user])))) > 0: violations_found += 1 #Pretty print deduplicated users print "\n--((List of Deduplicated Users))--" print " -- Num Users: " + str(len(set_users)) print " -- Num Emails: " + str(len(set_emails)) pretty_print_dict(users) #Print out report print "\n--((Assertion Evaluation))--" print " -- Users look unique and correct!" if len(set_users) == correct_num_users else " -- These users don't look right." print " -- Emails look unique and correct!" if len(set_emails) == correct_num_emails else " -- These emails don't look right." print " -- Duplication Violations found: " + str(violations_found) |
Thirdly, we wanted to test our algorithm on a variety of unbiased inputs, so we build a random generator that would construct random user and email sets. This generator takes a few inputs, namely the number of users to generate and a probability function that describes the odds of having 1 - E emails in each user. Additionally, a variety parameter was used to control the rate of collision of users having duplicated emails.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | def gen_random_users(N = 10, tiers = [0.70, 0.80, 0.90, 0.95, 0.98, 0.99, 0.999], V = 1): """generates a random dictionary of users and emails :param: N controls the number of users to be generated :param: tiers controls the probabilities of increasing numbers of emails per user :param: V controls the variety of the emails generated. Higher V = less chance of duplicate returns users - a list of random users with random emails """ users = {} set_emails = set([]) variety = V*N/10 for i in range(1,N+1): #gen random list of emails f = random.random() for t,tier in enumerate(tiers): if f < tier: n = t+1 break emails = [] for j in range(n): emails.append(random.randint(1,10+variety)) emails = list(set(emails)) emails = ['e'+str(e) for e in emails] for email in emails: set_emails.add(email) users[tuple(['u'+str(i),])] = emails return users, N, len(set_emails) |
Comparing Brute Force to Graph Theory
Our Brute Force algorithm is O(N^3) and the Graph Theory approach is O(N^2). Our Graph Theory approach should be much faster, right? Indeed. When run on the same set of users, we can see dramatic speeds. For larger N, these speedups would be even faster.
For one random case of 10 users, our Brute Force approach took 2.149 seconds, while our Graph Theory approach took 0.001 seconds, indicating a speedup of over 2000x. This greatly varies, since our two algorithms have different strong and weak points.
For 50 users, it is generally very difficult for the Brute Force approach to work in any bearable amount of time, while the Graph Theory approach can run in mere fractions of a second. I was able to see bearable runtimes up to N=50000 in about 9 seconds, but when we tweak the random generator so that most emails are never duplicated, the runtime for Graph Theory approach increases, and N=2000 would run in about 4 seconds (yet still, at large N, Graph Theory approach would win over Brute Force in any situation).
Connected Components
A similar application, Strongly Connected Components, occurs only in directed graphs. In our application, we utilized general undirected graphs, so any node within a connected component could be reached from any other node in the same connected component. With directed graphs, we encounter situations where we may not be able to return to a node once we left it. One algorithm for solving the problem of strongly connected components is Tarjan's Algorithm. The general idea here, is that any cycle or a single vertex is a strongly connected component.
Full Source Code
Source code available here: http://pastebin.com/gKxYuEHC
No comments:
Post a Comment